

- What is the Site Reliability Engineering (SRE) Model?
- Organizational Impact of SRE: Transforming Teams & Systems
- Business Benefits of SRE: Why It Matters for Organizations
- SRE Case Studies: Real-World Impact of SRE
- Challenges Organizations Face with SRE Adoption
- Conclusion
- Next Step: Become an SRE Expert
Site Reliability Engineering (SRE) has transformed the way businesses operate, bringing immense benefits like reliable systems, efficiency, and faster delivery. The organizational impact of SRE is undeniable in 2025, with organizations adopting SRE practices to increase operational efficiency, manage risk better, and deliver superior customer satisfaction. The ability of SRE to seamlessly blend reliability with innovation has made it a vital aspect of modern IT organizations.
What is the Site Reliability Engineering (SRE) Model?
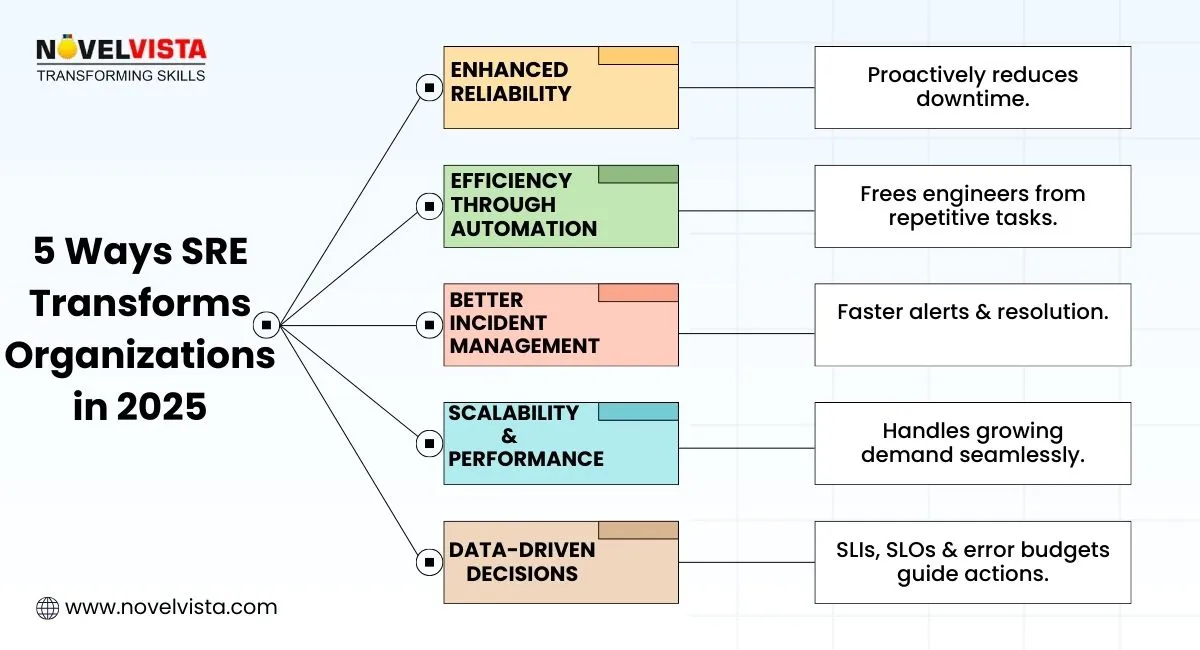
Site Reliability Engineering is a discipline that combines software engineering and IT operations to ensure reliable, scalable, and efficient systems. The SRE model extends beyond traditional IT operations by employing software engineering techniques to automate and enhance system reliability and performance. Here’s how it impacts organizations:
- Enhanced Reliability & Availability: SRE helps keep systems stable and reduces downtime by proactively addressing issues before they impact users.
- Efficiency Through Automation: A core principle of SRE is automating repetitive tasks, which reduces manual errors and frees up engineers for more valuable work.
- Improved Incident Management: SRE focuses on faster detection, alerts, and resolution of incidents, ensuring that service disruptions are minimal.
- Scalability & Performance Optimization: SRE ensures that systems can scale efficiently, enabling businesses to meet growing demands without compromising performance.
- Data-Driven Decisions: The SRE approach relies on SLIs (Service Level Indicators), SLOs (Service Level Objectives), and error budgets to drive data-informed decision-making.
While SRE shares some similarities with DevOps (in its focus on collaboration between development and operations), it goes further by emphasizing reliability as the central metric for success, making it an essential practice for modern businesses.
30-Day SRE Learning Plan
- Master SRE skills, tools, and
- practices with this step-by-step roadmap before others catch up.
Organizational Impact of SRE: Transforming Teams & Systems
Implementing SRE leads to profound changes in both technical practices and organizational culture. Here’s how the organizational impact of SRE plays out:
- Getting Ahead of Incidents: By focusing on proactive monitoring, SRE teams can anticipate and resolve potential issues before they turn into full-blown incidents. This proactive approach reduces system downtime, leading to better user experiences and lower operational costs.
- Analyzing and Improving DevOps Processes: SRE doesn’t just respond to incidents; it continuously optimizes DevOps processes for faster and more efficient delivery. With SRE’s focus on continuous improvement, businesses can identify bottlenecks in the system and streamline their workflows for quicker go-to-market times.
- Learning From Every Incident with Retrospectives: One of the key practices of SRE is the blameless post-mortem. After every incident, SRE teams conduct a thorough review to learn from the event and improve processes. This culture of continuous improvement helps organizations reduce the frequency and severity of incidents over time.
- Aligning Teams on User Happiness: The organizational value of SRE extends to customer satisfaction. By focusing on reliable systems and minimizing downtime, SRE ensures that users have a seamless experience with the organization’s digital products, which boosts customer retention and loyalty.
- Minimizing On-Call and User Pain: SRE’s emphasis on automation and proactive incident management significantly reduces the number of on-call shifts and user pain. This allows teams to focus on innovation rather than firefighting operational issues, ultimately improving work-life balance for IT professionals.
- Empowering Teams Through Cultural Change: SRE fosters collaboration between development and operations teams, breaking down silos. It also encourages psychological safety, where engineers feel empowered to take risks and experiment with new solutions.
Industry Insight: Organizations that have fully integrated SRE practices often report a 20–40% reduction in downtime incidents and significant improvements in team collaboration. These outcomes aren’t just theory; they are observed in real-world transformations across sectors like retail, finance, and SaaS. By embedding reliability into development lifecycles, companies achieve measurable operational improvements and long-term resilience.
Business Benefits of SRE: Why It Matters for Organizations
When an organization implements SRE, it reaps a wide range of business benefits:
- Increased Customer Satisfaction: Reliable systems that minimize downtime directly lead to happier users. SRE ensures that customers can rely on your services without interruptions, improving their overall experience.
- Cost Efficiency: Automation and the proactive nature of SRE reduce manual interventions, operational overhead, and the cost of system failures. By minimizing these inefficiencies, organizations can direct resources to innovation.
- Competitive Advantage: Reliability and continuous improvement are powerful differentiators in a competitive market. Companies with strong SRE business impact attract more customers and partners due to their ability to provide dependable services.
- Faster Innovation Cycles: With SRE practices in place, IT teams spend less time dealing with incidents and more time building new features, which accelerates the company’s ability to innovate.
- Resilient and Scalable Systems: SRE ensures that systems are not only reliable but also scalable, meaning businesses can meet the growing demands of their users without sacrificing performance.
SRE Case Studies: Real-World Impact of SRE
Google: Safe Proxies – Boosting Security and Reliability
Google’s Safe Proxies use Site Reliability Engineering (SRE) practices to improve the security and reliability of its production systems. These proxies act as intermediaries, controlling access and ensuring that only authorized requests reach critical systems.
Key Benefits:
- Access Control: Proxies limit who can access important systems.
- Auditing: All actions are logged for transparency.
- Rate Limiting: Helps prevent system failures by controlling how often changes are made.
- Legacy Support: Allows secure communication with older systems that don’t have modern security features.
The Safe Proxies initiative is part of Google’s Zero Touch Production (ZTP) system, which automates and checks all changes to reduce mistakes and outages. While effective, it requires regular maintenance to avoid potential risks.
In short, Safe Proxies show how SRE practices can make systems more secure and reliable while reducing risks from privileged access.
(Source: Safe Proxies)
Evernote: Implementing SLOs to Align Development and Operations
Evernote, a cross-platform application with over 220 million users, embarked on its Site Reliability Engineering (SRE) journey in April 2017. The initiative aimed to bridge the gap between development and operations teams, fostering a shared responsibility for service reliability.
Key Initiatives:
- Transition to Public Cloud: Moved away from physical data centers to enhance scalability and reduce operational overhead.
- Adoption of SLOs: Implemented Service Level Objectives (SLOs) to provide clear reliability targets, moving beyond traditional SLAs.
- Shared Responsibility Model: Encouraged developers to take ownership of the entire service lifecycle, including monitoring and incident response.
- Integration with Monitoring Tools: Utilized Datadog for tracking SLOs and integrated with Google Stackdriver for enhanced visibility and alerting.
Through these efforts, Evernote successfully aligned its engineering teams, improved service reliability, and enhanced customer satisfaction.
(Source: Evernote)
The Home Depot: Establishing a Culture of SLOs for Service Reliability
The Home Depot, the world's largest home improvement retailer, embarked on a significant transformation to enhance the reliability of its services. With over 2,200 stores and a vast online presence, the company recognized the need for a unified approach to service reliability.
Key Initiatives:
- Adoption of Microservices Architecture: Transitioned from monolithic systems to microservices, enabling independent development and deployment.
- Implementation of SLOs: Introduced Service Level Objectives (SLOs) to define and measure service reliability, focusing on metrics such as availability, latency, and error rates.
- Cultural Shift: Promoted a "freedom and responsibility" culture, empowering development teams to own both the development and operational aspects of their services.
- Automation of Metrics Collection: Developed the TPS Reports framework on Google Cloud Platform's BigQuery to automate the collection and analysis of SLO data.
- Creation of VALET Framework: Established the VALET (Volume, Availability, Latency, Errors, Tickets) framework to standardize and simplify SLO definitions across the organization.
Through these initiatives, The Home Depot successfully integrated SLOs into its development processes, fostering a culture of accountability and continuous improvement. This approach has led to enhanced service reliability and a more collaborative environment between development and operations teams.
(Source: The Home Depot)Challenges Organizations Face with SRE Adoption
Despite the significant benefits, SRE adoption comes with challenges:
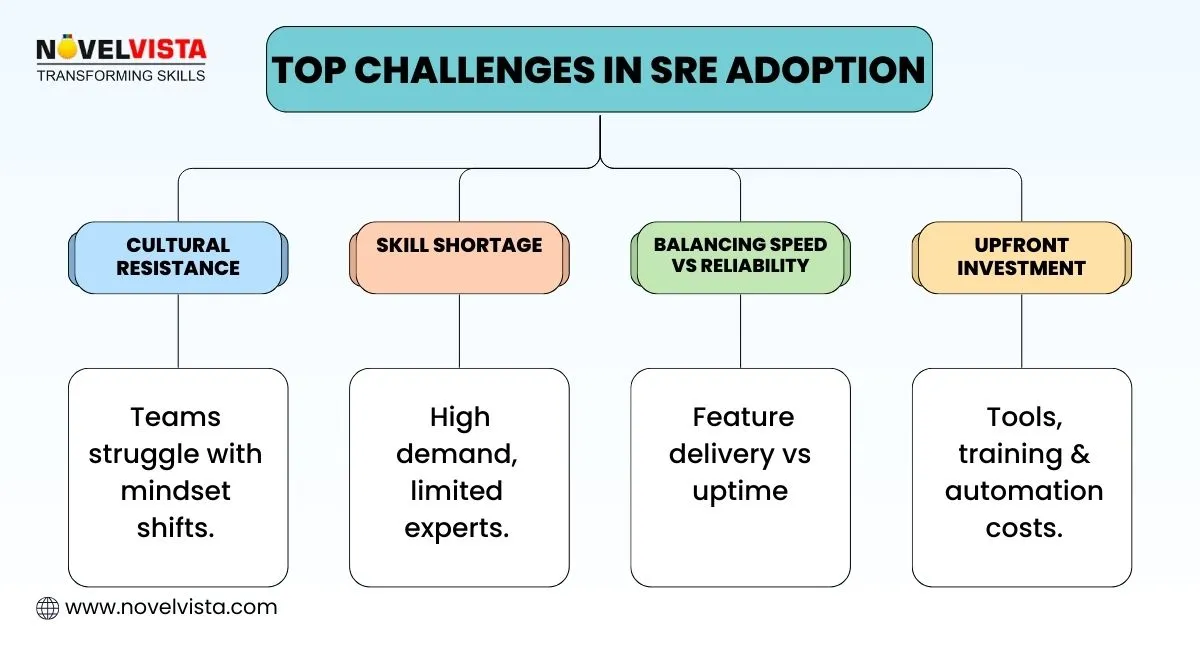
- Resistance to Cultural Change: Shifting to an SRE model requires changes in organizational culture, which may face resistance from teams accustomed to traditional IT operations.
- Shortage of Skilled SRE Professionals: The demand for skilled SRE professionals is high, and organizations may struggle to find the right talent to implement SRE practices.
- Balancing Feature Delivery with Reliability: While SRE emphasizes reliability, it can sometimes be challenging to balance the demands of innovation with the need to maintain system stability.
- Upfront Investment: Implementing SRE practices requires investment in tools, training, and automation, which can be a barrier for some organizations.
Conclusion
The organizational impact of SRE goes far beyond simply improving service reliability; it drives business growth, enhances customer satisfaction, and provides a competitive edge. By focusing on both operational stability and innovation, SRE enables organizations to scale more effectively and efficiently. If you’re looking to future-proof your organization’s IT infrastructure, adopting SRE principles is the key to long-term success.
Next Step: Become an SRE Expert
Ready to unlock the potential of SRE for your organization? NovelVista’s SRE Foundation Certification is designed to equip you with the knowledge, tools, and practices to implement SRE in your organization. Whether you're an engineer, manager, or IT leader, this certification empowers you to enhance your systems’ reliability and performance.
Frequently Asked Questions
Author Details

Vaibhav Umarvaishya
Cloud Engineer | Solution Architect
As a Cloud Engineer and AWS Solutions Architect Associate at NovelVista, I specialized in designing and deploying scalable and fault-tolerant systems on AWS. My responsibilities included selecting suitable AWS services based on specific requirements, managing AWS costs, and implementing best practices for security. I also played a pivotal role in migrating complex applications to AWS and advising on architectural decisions to optimize cloud deployments.
Confused About Certification?
Get Free Consultation Call




